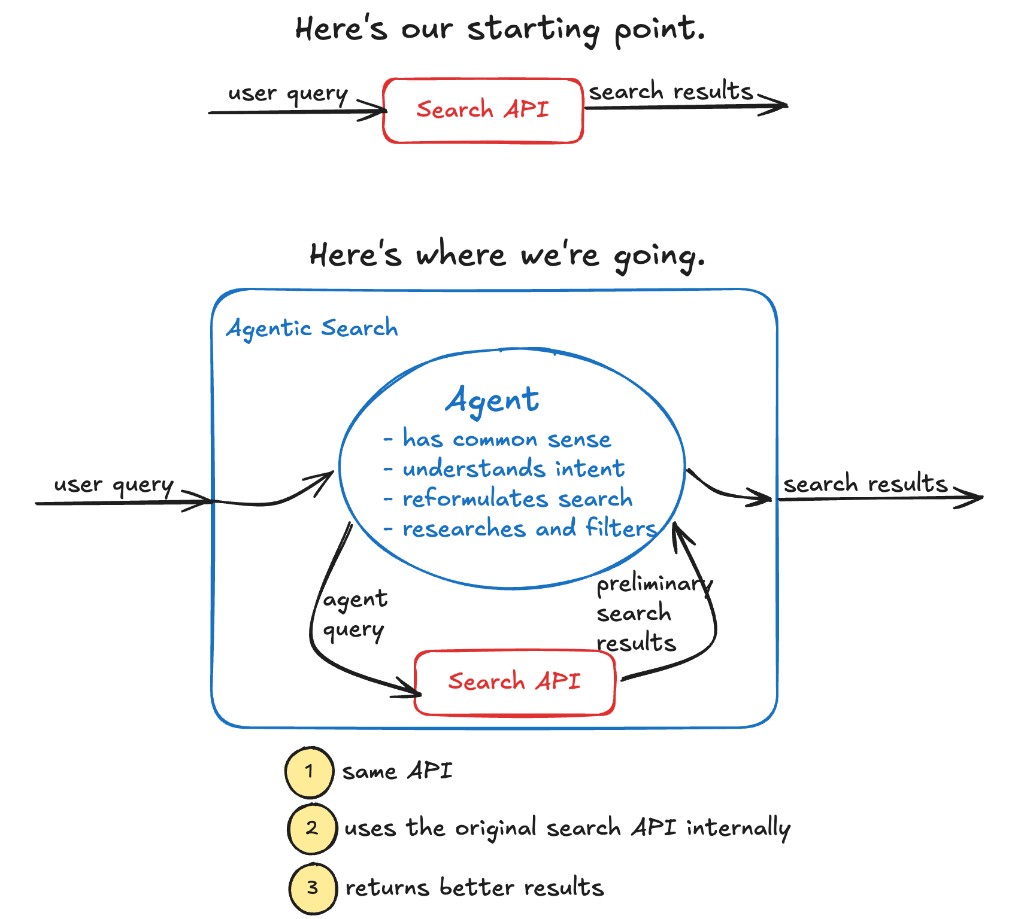
Moving from traditional search to something smarter used to be very challenging. Before the current AI revolution, you basically had to hire a full-time machine learning team. But now you can skip all that extra cost and effort.
Let's face it, RAG can be a big pain to set up, and even more of a pain to get right.
There's a lot of moving parts. First you have to set up retrieval infrastructure. This typically means setting up a vector database, and building a pipeline to ingest the documents, chunk them, convert them to vectors, and index them. In the LLM application, you have to pull in the appropriate snippets from documentation and present them in the prompt so that they make sense to the model. And things can go wrong. If the assistant isn't providing sensible answers, you've got to figure out if it's the fault of the prompt, the chunking, or the embedding model.
If your RAG application is serving documentation, then there might be an easy alternative. Rather than setting up a traditional RAG pipeline, put the LLM assistant to work. Let it navigate through the documentation and find the answers. I call this "Roaming" RAG, and in this post I'll show you how it's done.
In information retrieval, we often find ourselves between two tools: keyword search and semantic search. Each has strengths and limitations. What if we could combine the best of both?
By the end of this post, you will:
Understand the challenges of keyword and semantic search
Learn about SPLADE, an approach that bridges these methods
See a practical implementation of SPLADE to enhance search
If you've struggled with inaccurate search results or wanted a more transparent search system, this post is for you. Let's explore how SPLADE can change your approach to information retrieval.